Nine layers between electrons and tokens
A map of the AI compute stack, pulled apart one layer at a time, with the failure modes drawn in.
Jensen Huang sat with Dwarkesh Patel for an hour and forty minutes in April 2026 and offered a framing that has since been quoted in every AI earnings call: the input is electrons, the output is tokens, in the middle is Nvidia. He called it a five-layer cake. Energy at the bottom. Chips, systems, models, and applications stacked on top. Useful, so far as it goes.
The frame is also partial. Jensen's interests are silicon, supply chain, and China policy, so that is what he talks about. The real AI ecosystem is wider than the cake he slices. It has parallel pipelines that feed into the stack sideways. It has a ring of forces pressing in from outside. It has failure modes that span layers in ways no vertical diagram captures.
This piece is a full map. I have expanded the five-layer cake to nine layers, added the parallel streams Jensen does not sell into, drawn in the external forces that constrain the whole thing, and built a small simulator so you can break pieces of the stack and watch the cascade. The point is not to correct Jensen. He is describing a company. The point is to describe the system that company sits inside, because most public arguments about AI are reasoning about one layer and ignoring the other eight.
AI policy debates that live at a single layer are almost always wrong. Export controls are an L2 lever with L6 consequences. Copyright litigation hits an invisible L5 stream. Energy permitting at L0 is why your favourite model's next version is late. You cannot reason about any of this from one altitude.
Part oneThe stack, laid out
Jensen's five layers compress too much. Breaking the cake into nine gives you enough resolution to see where the interesting arguments actually live. Reading top-down, from what users see to what physically moves through silicon:
L8. Applications. Chatbots, coding assistants, embedded copilots. Claude, ChatGPT, Cursor, Copilot. The only layer that touches a user. Every value claim made by lower layers has to resolve here.
L7. Serving. The runtime between a frozen model and a user request. KV-cache, batching, speculative decoding, quantisation. vLLM, SGLang, TensorRT-LLM. A 2x improvement in serving is a 2x margin improvement on every token sold.
L6. Models. Architecture plus weights. Claude, GPT, Gemini, DeepSeek. Capability comes half from architecture, half from training procedure. Dense, MoE, hybrid SSM, diffusion. The file of numbers that takes ten to a hundred million dollars to make.
L5. Frameworks. PyTorch, JAX. Turn Python math into scheduled kernel launches across thousands of GPUs. Autograd, device placement, compilation. PyTorch dominates research. JAX wins on TPU.
L4. Kernels. CUDA, Triton, cuBLAS, NCCL, FlashAttention. Code that runs on silicon. A hand-tuned kernel can beat generic compiled code by three to five times. Across a trillion-parameter model, that is the difference between a billion and three billion dollars of compute.
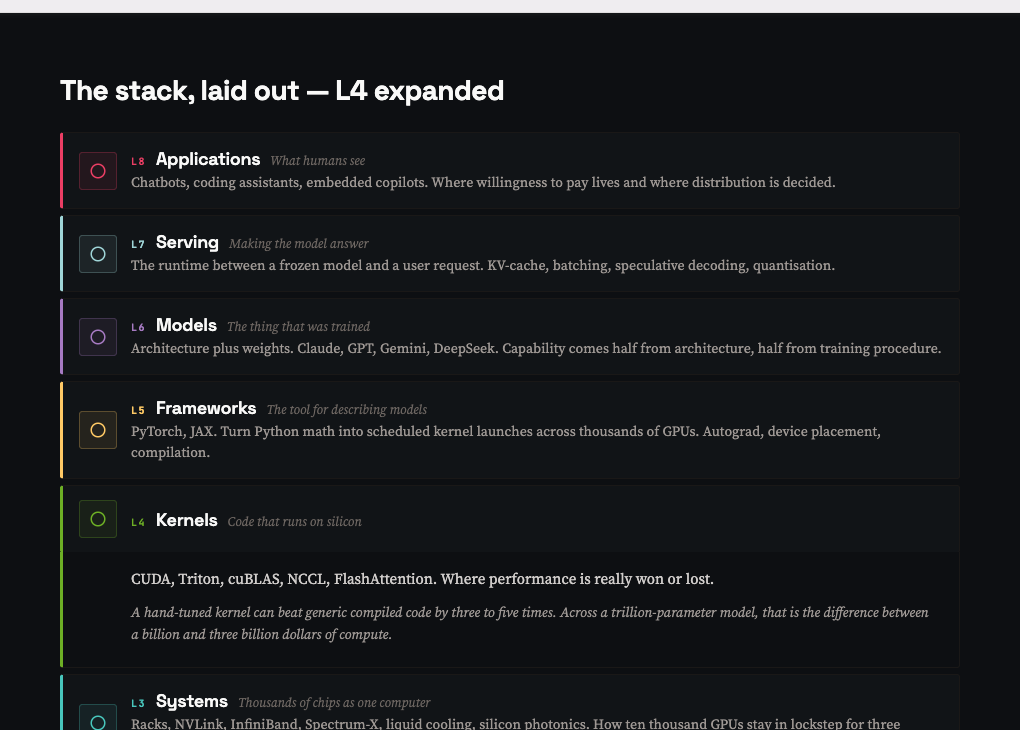
L3. Systems. Racks, NVLink, InfiniBand, Spectrum-X, liquid cooling, silicon photonics. How ten thousand GPUs stay in lockstep for three months. The fabric design, cable lengths, power distribution, and cooling topology all conspire to determine whether GPUs compute or wait.
L2. Chips. H100, B200, TPU, Trainium, Huawei Ascend. Compute die plus HBM stacks on a silicon interposer. Every chip design is a compromise between compute density, memory bandwidth, heat dissipation, and TSMC's packaging capacity.
L1. Silicon. TSMC, Samsung, SMIC foundries. ASML lithography. EDA tools from Cadence and Synopsys. A 300mm wafer goes through several hundred process steps to become chips. EUV machines cost 200 million dollars each, and ASML ships fewer than sixty per year.
L0. Energy. Grid power, gas turbines, nuclear restarts, behind-the-meter generation. The binding constraint. Every layer above is a machine for turning electricity into organised information. Frontier training runs consume tens of megawatt-years. Permitting a new substation takes three to five years.
The bottleneck has migrated every year since 2023. GPU supply became the binding constraint in 2023. CoWoS packaging in late 2023. HBM memory through 2024. Power interconnection in 2025 and 2026. The constraint keeps moving because every time one layer opens up, attention flows to the next tightest one. If you want to predict where AI supply chains go next, watch which layer is currently scarce.
Jensen is explicit about which layer he fears most: energy. Every other bottleneck has a two to three year resolution timeline. Permitting a new substation, building new generation, restarting nuclear plants, all of those take four to seven years. This is why hyperscalers are signing direct deals with nuclear operators and standing up gas turbines behind the meter. The grid is not going to save them in time.
Part twoWhat the pod did not say
The vertical stack is necessary but not sufficient. Five things run alongside it that never appear in Jensen's frame, either because they are not his business or because naming them weakens his argument.
Parallel pipelines
Each of these is its own ecosystem. Separate companies, separate margins, separate bottlenecks. They feed the stack sideways, at specific layers.
Data. Pre-training corpora, licensed publisher deals, synthetic data, human preference labels. Invisible from the chip seat. Determines model capability as much as hardware does.
Training infrastructure. Orchestration, checkpointing, fault tolerance, distributed parallelism, Megatron, FSDP. Distinct from inference. Rare expertise, high compensation, the quiet engineering behind every frontier model.
Alignment and safety. RLHF, Constitutional AI, red-teaming, dangerous capability evaluations, interpretability. Can gate deployment even when compute works perfectly. Creates market asymmetries between cautious and permissive jurisdictions.
Agents and tooling. Function calling, MCP, Computer Use, RAG, vector databases, memory systems, agent frameworks. The bit that turns a text generator into a system that does things. Reliability is the blocker.
Evaluation. MMLU, SWE-bench, LMSYS Arena, Langfuse, internal benchmarks. The only honest way to know if any of the rest is working. Benchmark integrity is a permanent arms race.
Notice data. Nobody thinks of it as infrastructure. It is. The NYT lawsuit against OpenAI is an L5 parallel-stream event that reaches into L6 and suspends basic training economics across every frontier lab. Jensen does not mention data once in the interview, because his chips do not care what tokens they grind. But Anthropic and OpenAI and Google care, and what they care about shapes which models get built, which shapes what L8 products exist, which shapes the whole thing.
The outer ring
And then the external forces. These do not slot into any one layer. They constrain, fund, police, or are emitted by the whole stack.
Capital. Frontier compute now costs more than VCs can write cheques for. Sovereign wealth and hyperscaler balance sheets fill the gap. Jensen missed Anthropic because Nvidia was not yet in the checkbook class.
Talent. The top thousand researchers do not scale. More capital chasing the same pool only inflates compensation. The real moat at frontier labs is that they keep their people.
Regulation. EU AI Act in force. US export controls shape the China debate. Copyright litigation suspends basic training-data economics. Pace of regulation versus pace of capability is permanently mismatched.
Geopolitics. TSMC concentration risk has no feasible contingency plan. Sovereign AI programmes multiplying. Open-weights diffusion from China routes around bilateral controls.
Environment. Data centres projected at eight to twelve percent of US electricity by 2030. Water stress in Arizona and central Taiwan. Rare earth and copper supply chains concentrated in specific countries.
Each tier has communities that ignore the other two. Silicon Valley talks the vertical stack. Academia and safety organisations focus on alignment and evaluation. Policy people care about regulation and geopolitics. Environmentalists are finally noticing the physical footprint. Almost every public debate on AI is fought by people reasoning confidently about one tier and waving the other two away.
Part threeHow it breaks
The payoff of a good system map is that you can trace failures. A static diagram tells you what exists. A dependency graph tells you what catches fire when something drops. Below is a simplified version of the stack wired for cascades. The Taiwan Strait scenario is loaded: TSMC fails, and the cascade propagates.
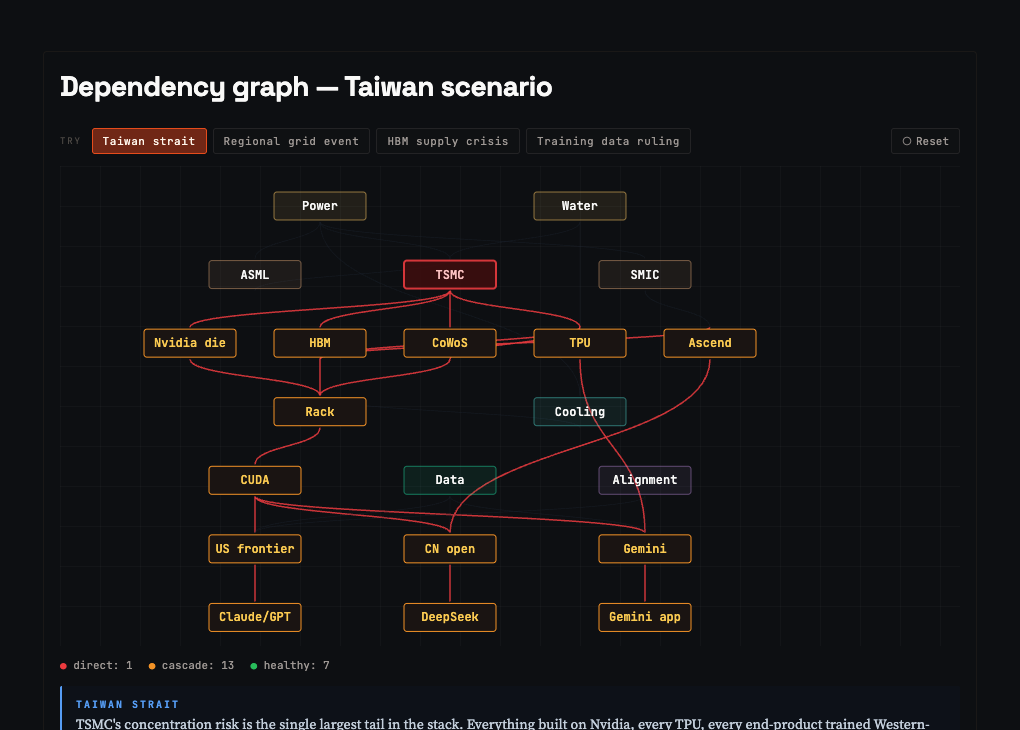
The most instructive failure is HBM. One memory supplier goes down and you lose Nvidia, TPU, and Huawei Ascend in a single move. Nowhere else in the stack does a single component have that reach. This is why SK Hynix and Micron carry the premium valuations they do, and why every AI accelerator roadmap is quietly gated on HBM4 availability.
The other instructive cascade is copyright. Kill training data and you do not break any silicon, but you freeze the next generation of models across every Western lab. Nothing at L0 through L4 notices. Everything at L6 and above slows to a crawl. The parallel pipelines matter exactly as much as the vertical stack.
Part fourThe inch that matters
Almost all the money and attention in AI right now is being spent at L2 through L6. Chips, systems, kernels, frameworks, models. Several hundred billion dollars of capital expenditure annually, a dozen companies that matter, TSMC in the middle of it holding everyone's throat. This is where Jensen sells. This is also where almost no one else has any business trying to compete.
The inch of the stack that remains under-invested is the last millimetre of L8. The bit where a configured AI meets an actual human's life. Consider what this looks like for a typical urban Indian professional in 2026. Their WhatsApp is unsummarised. Swiggy is endless scrolling. Myntra cannot find them a long shirt because their measurements live nowhere. Their email triage is still manual. Their meetings are unnoted. Their context resets every session.
The technical primitives to fix all of this exist. The models are smart enough. The context windows are long enough. The MCP-style interface standard is open. What is missing is the personal wrapper, a persistent, opinionated, memory-equipped layer that holds the user's rules and drives every AI-capable surface on their behalf. Rewind tried in 2023 and was too early. Personal.ai tried and never productised. Nobody has done it for the Indian power user at all.
Shopify did not beat Amazon. It gave every merchant a way to sell their own thing on their own terms using the same underlying capabilities Amazon had. The equivalent for AI is: every principal, every institution, every practitioner gets their own configured Claude that speaks in their voice and follows their rules and uses their tokens. The model is a utility. The configuration is the product.
The opportunity is not to build a better Claude. Claude is an excellent Claude. The opportunity is to build the configuration layer around it, the one that knows your voice, your rules, your history, your constraints, and sell that configuration to people who will not build it themselves.
Someone is going to build this in India over the next three years. The technical bar is not high. The voice capture is a specialist skill that happens to overlap with communications professionals rather than engineers. The distribution channels, X, LinkedIn, Substack, institutional networks, are open and under-exploited. And the incumbents are not coming. Anthropic is not going to tune Computer Use for Swiggy. OpenAI is not going to build voice-matched drafting for Indian ministerial offices. That work will be done locally or not at all.
I am going to write about this for the rest of 2026. If that interests you, follow along. The essays will map the emerging shape of this market in India, document what I build and what breaks, and report back from the inside of institutional communications work during the first real wave of AI deployment. This piece is the foundation. The rest follows.
If this frame holds, follow along. Weekly logs at @iamitp, longer maps here. What I build, what breaks, and what happens to ministerial drafts when the configuration layer starts doing its job.